IA y GEO
Comparación de Claude con otras IA: razonamiento y código
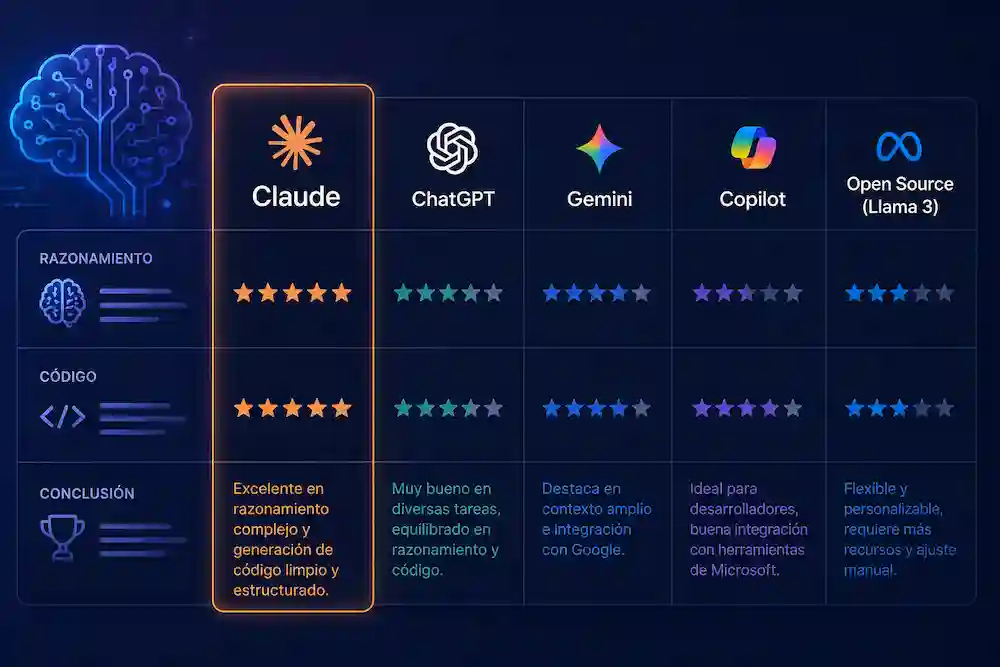
Claude ya compite de tú a tú con GPT y Gemini en código y razonamiento, pero sus ventajas reales aparecen cuando el trabajo se complica mucho
La comparación de Claude con otras IA para razonamiento y código deja una respuesta menos cómoda que el típico ranking de feria: Claude no gana siempre, pero cuando el trabajo exige leer mucho contexto, tocar una base de código grande, mantener instrucciones finas y no inventarse una salida bonita, está entre los modelos más fiables del mercado. En mayo de 2026, el nombre fuerte dentro de Anthropic es Claude Opus 4.7, presentado como su modelo más capaz para razonamiento complejo y programación agentiva, mientras Claude Sonnet 4.6 queda como la opción de equilibrio entre inteligencia, velocidad y uso en producción.
El titular práctico es este: Claude brilla más en código difícil que en respuestas vistosas. GPT-5.5 aprieta mucho en autonomía de terminal, herramientas y flujos largos; Gemini 3.1 Pro conserva músculo en razonamiento multimodal, ciencia y contexto gigantesco; DeepSeek y Mistral empujan desde el terreno abierto o semiaabierto con precios y despliegues más flexibles. Pero Claude tiene una virtud menos glamourosa y más valiosa: suele comportarse como un programador prudente, de esos que antes de tocar producción preguntan dónde está el cable de tierra.
El veredicto útil: Claude gana cuando el código se complica
Claude no es “mejor IA” en abstracto, porque esa etiqueta ya no sirve. Es mejor en determinados trabajos: revisión de código, refactorizaciones con muchas dependencias, explicación de errores, análisis de repositorios amplios, generación de pruebas, migraciones delicadas y tareas en las que una IA debe recordar qué prometió diez pasos atrás. Ahí Anthropic ha hecho de la continuidad una marca de fábrica. Opus 4.7 está orientado a análisis complejo, código y tareas creativas que requieren razonamiento profundo, mientras Sonnet 4.6 se coloca como la pieza razonable para producción diaria.
En las pruebas más observadas del sector, Claude Opus 4.7 aparece especialmente fuerte en SWE-Bench Pro, una evaluación centrada en resolver incidencias reales de GitHub: 64,3% para Claude Opus 4.7, frente al 58,6% de GPT-5.5 y el 54,2% de Gemini 3.1 Pro. Ese dato no convierte a Claude en rey eterno del código, pero sí explica por qué muchos desarrolladores lo perciben como una herramienta especialmente cómoda para tareas de ingeniería de software real: no solo escribir una función, sino tocar una pieza dentro de una máquina que ya vibra, se queja y tiene deuda técnica escondida bajo la alfombra.
La diferencia se nota en el tipo de fallo. Claude suele fallar con cautela: puede ser más lento, puede pedir más contexto, puede negarse a dar una respuesta cerrada cuando detecta huecos. Esa prudencia irrita cuando uno quiere velocidad, pero salva tiempo cuando el problema es ambiguo. En código, una mentira elegante cuesta cara. Un test verde por casualidad es un billete falso. Y Claude, al menos en sus versiones recientes, parece entrenado para no venderte tan alegremente esa moneda brillante.
Claude frente a GPT: bisturí contra excavadora
La rivalidad con GPT es la comparación inevitable. GPT-5.5 se presenta como uno de los modelos más fuertes de OpenAI para programación agentiva, con una puntuación del 82,7% en Terminal-Bench 2.0, una prueba pensada para flujos complejos de línea de comandos que exigen planificación, iteración y coordinación con herramientas. En esa misma tabla, Claude Opus 4.7 figura con 69,4% y Gemini 3.1 Pro con 68,5%. Aquí GPT no gana por escribir una función más limpia, sino por moverse mejor dentro de un entorno operativo: abrir, probar, corregir, volver a intentar.
Traducido al trabajo diario: GPT-5.5 puede ser más fuerte cuando el encargo parece una tarde entera de terminal. Levantar un proyecto, instalar dependencias, perseguir errores, cambiar archivos, ejecutar pruebas y cerrar una tarea larga sin perder el hilo. OpenAI también le atribuye mejoras en uso de herramientas, documentos, hojas de cálculo y trabajo profesional amplio, con disponibilidad en ChatGPT y Codex para usuarios de pago y despliegue API anunciado con una ventana de contexto de 1 millón de tokens.
Claude, en cambio, da una sensación distinta. Menos tractor, más cirujano. En una migración de frontend, por ejemplo, GPT puede avanzar con más energía si se le deja trabajar como agente; Claude suele ser más fino explicando por qué una arquitectura se rompe, dónde conviene separar responsabilidades, qué test falta y qué cambio pequeño reduce el riesgo. No siempre. Pero lo bastante a menudo como para que la elección no sea trivial.
Cuando manda la terminal
El dato importante para empresas, agencias y equipos de marketing técnico no está en el marcador absoluto, sino en el coste del error. Para prototipar rápido, GPT resulta muy competitivo. Para revisar una integración crítica, Claude puede inspirar más confianza. Para documentación, estrategia técnica y decisiones de producto con código por debajo, ambos sirven, aunque con temperamentos distintos: GPT empuja; Claude ordena.
En trabajos de línea de comandos, GPT suele comportarse como una excavadora con buen GPS: avanza, corrige, itera, vuelve a cargar. Claude parece más un revisor de arquitectura con lápiz rojo, algo pesado a veces, sí, pero útil cuando un pequeño cambio puede romper una cadena de dependencias. En programación real, esa diferencia pesa. Y mucho. Porque el problema rara vez es escribir diez líneas impecables; el problema es tocar diez líneas dentro de un castillo levantado por seis personas, tres urgencias y un viernes por la tarde.
Gemini, DeepSeek y Mistral: los otros rivales serios
Gemini 3.1 Pro entra en la comparación con otra personalidad. Google lo sitúa como un modelo avanzado para tareas complejas, capaz de manejar texto, audio, imagen, vídeo y repositorios completos, con una ventana de contexto de hasta 1 millón de tokens y salida de 64.000 tokens. No es poca cosa. Es una IA pensada para tragar bibliotecas, no para picotear frases sueltas.
En razonamiento académico y científico, Gemini aparece muy fuerte. Sus registros públicos lo colocan en posiciones altas en pruebas como GPQA Diamond, ARC-AGI-2 y Humanity’s Last Exam, con evaluaciones centradas en razonamiento, capacidades multimodales, uso agentivo de herramientas, rendimiento multilingüe y contexto largo. Esa combinación lo vuelve especialmente interesante para tareas donde el código no vive solo: análisis de documentos, imágenes, gráficos, vídeos, datasets y explicaciones técnicas con mucha materia prima alrededor.
La pega, en comparación con Claude, aparece cuando se baja del laboratorio al taller. En programación pura, sobre todo en resolución de incidencias reales, Gemini 3.1 Pro no queda mal, pero no lidera frente a Claude Opus 4.7 en SWE-Bench Pro. A cambio, Gemini puede ser una opción más sólida cuando el trabajo mezcla código con material visual, investigación, PDFs, vídeos, capturas, presentaciones y contexto empresarial largo. Es decir: menos “arréglame este bug” y más “entiende todo este sistema antes de tocar nada”.
Para un blog de SEO, SEM y marketing digital, esto importa más de lo que parece. Gemini puede rendir muy bien en auditorías multimodales, por ejemplo al cruzar capturas de Search Console, documentos de estrategia, hojas con keywords, briefings de cliente y código de una plantilla. Claude suele ser más cómodo cuando hay que convertir ese diagnóstico en una explicación técnica clara o en una intervención prudente sobre HTML, JavaScript, schema o automatizaciones.
El peso de los modelos abiertos
La conversación no se agota en Anthropic, OpenAI y Google. DeepSeek V4 llegó en abril de 2026 con una propuesta especialmente agresiva: versión Pro y Flash, pesos abiertos, contexto de 1 millón de tokens y una arquitectura orientada a reducir costes de cómputo y memoria en contextos largos. DeepSeek presenta V4-Pro como un modelo de alto rendimiento para capacidades agentivas, conocimiento, razonamiento y código, mientras V4-Flash apunta a velocidad y precio.
DeepSeek también tiene una lectura geopolítica nada menor: su adaptación a chips Huawei Ascend encaja dentro de la carrera china por reducir dependencia tecnológica exterior. El modelo se posiciona como competitivo en programación agentiva, STEM y competición de código, aunque en algunas áreas seguiría por detrás de sistemas cerrados de frontera como Gemini y GPT. Aquí ya no hablamos solo de rendimiento: hablamos de poder industrial, soberanía tecnológica y quién paga la electricidad de la fiesta.
Mistral juega otra partida: modelos abiertos, despliegue flexible y foco europeo. Su catálogo destaca Mistral Large 3 como modelo general multimodal de pesos abiertos, Devstral 2 como modelo de agentes de código para resolver tareas de ingeniería de software y Mistral Medium 3.5 como opción multimodal optimizada para casos agentivos y de programación. No compite siempre por el titular del benchmark, pero sí por algo más prosaico: control, coste, soberanía tecnológica y posibilidad de montar soluciones propias sin entregar todas las llaves al vecino.
Ahí Claude tiene una debilidad evidente: es un modelo cerrado. Excelente, sí; cómodo, también; potente, desde luego. Pero si una empresa necesita auditar pesos, autoalojar, ajustar infraestructura o mantener determinados datos fuera de APIs externas, DeepSeek, Mistral y otros modelos abiertos cambian el cálculo. No todo se decide por quién razona mejor en una demo. A veces decide el departamento legal. Y a veces, más todavía, decide la factura.
Razonamiento real: equivocarse menos
La palabra razonamiento se ha convertido en una feria de luces. Todos los modelos “razonan”, todos “piensan”, todos “planifican”, todos “entienden”. Luego llega un caso real, con una instrucción contradictoria, una documentación vieja, un plugin mal configurado y un error que solo aparece en producción, y la poesía se cae del escenario. Razonar no es escribir mucho. Razonar es mantener una cadena de decisiones útil bajo presión.
En ese terreno, Claude suele destacar por tres rasgos: explica bien, respeta bastante el contexto y tiende a reconocer límites. Claude Opus 4.7 aparece en la zona alta de varios índices de inteligencia artificial junto a GPT-5.5 y Gemini 3.1 Pro, con mejoras en trabajo agentivo general, menor uso de tokens de salida frente a Opus 4.6 y una reducción clara de alucinaciones en pruebas de respuesta factual, aunque con más abstención. Esa última palabra importa: abstenerse no es glamour, pero en trabajos técnicos puede ser una forma de higiene.
GPT suele ser más lanzado. A veces acierta antes; a veces se precipita mejor vestido. Gemini puede absorber más formatos y mirar el problema desde más ángulos. Claude, cuando está fino, hace algo menos espectacular: reduce ruido. Para redactar documentación técnica, revisar una estrategia de implementación, detectar lagunas en un prompt de producción o explicar a un cliente por qué su automatización de contenidos está fabricando basura con una sonrisa, esa reducción de ruido vale dinero.
En programación, el razonamiento se mide en cosas muy terrenales. ¿Ha entendido la estructura del repositorio? ¿Ha visto que cambiar una función rompe otra? ¿Propone tests o solo optimismo? ¿Distingue entre parche y solución? ¿Sabe cuándo no tiene datos suficientes? Claude suele ser fuerte en esas zonas grises, donde no basta con generar código válido, porque lo difícil no es que compile una vez, sino que no incendie nada después.
Qué IA conviene para SEO, marketing y desarrollo web
Para una agencia SEO, un medio digital o un ecommerce, la elección no debería formularse como una pelea de gallos entre marcas. Claude conviene cuando el trabajo mezcla lenguaje, criterio editorial y código sensible. Por ejemplo: revisar una plantilla de WordPress, detectar problemas en datos estructurados, explicar por qué un bloque JavaScript está retrasando el renderizado, convertir una auditoría técnica en un texto comprensible para dirección o analizar el impacto de una migración web sin caer en el “toca esto y reza”.
GPT-5.5 encaja mejor cuando el flujo pide acción sostenida con herramientas: crear scripts, operar con terminal, automatizar tareas, iterar pruebas, montar prototipos, trabajar dentro de un entorno de desarrollo y cerrar tareas encadenadas. Su ventaja en Terminal-Bench 2.0 apunta precisamente ahí, a la capacidad de operar durante más pasos con menos supervisión. No es una diferencia menor; para equipos que ya viven en entornos agentivos, puede ser decisiva.
Gemini 3.1 Pro merece sitio cuando el trabajo exige multimodalidad de verdad. Si hay que analizar capturas, vídeos, documentos extensos, datos cruzados y repositorios largos, su ventana de contexto y su diseño multimodal lo convierten en un rival serio. No siempre será el mejor programador, pero puede ser el mejor lector de una mesa llena de papeles, pantallas y señales mezcladas.
DeepSeek y Mistral aparecen cuando pesan coste, control y despliegue. Para proyectos con presupuestos ajustados, infraestructura propia o necesidad de experimentar sin depender de un único proveedor, son alternativas cada vez menos exóticas. Todavía pueden requerir más ingeniería alrededor, más evaluación interna y más cuidado en seguridad, pero el mercado ya no mira a los modelos abiertos como herramientas de segunda. Ese tiempo pasó deprisa, como casi todo en la IA.
En contenidos, SEO y marketing digital hay otro matiz. Claude suele escribir con más contención y estructura argumental, menos anuncio de LinkedIn y más informe legible, aunque también puede caer en solemnidad si se le deja. GPT tiende a ser más versátil en estilos y formatos. Gemini funciona bien cuando se le alimenta con material amplio y heterogéneo. Ninguno sustituye criterio editorial. La IA puede ordenar la cocina, pero todavía no sabe del todo qué plato merece salir a sala ni qué titular merece pelear en Google Discover.
La pelea real está en el uso, no en el trofeo
La comparación honesta entre Claude y otras IA para razonamiento y código termina en una idea sencilla: Claude es una de las mejores opciones cuando importa la fiabilidad técnica, el contexto largo y la calidad del razonamiento aplicado al software, pero no barre a sus rivales en todos los terrenos. GPT-5.5 parece más fuerte en autonomía de terminal y ejecución larga con herramientas; Gemini 3.1 Pro conserva una posición notable en razonamiento multimodal y científico; DeepSeek y Mistral presionan por abajo y por los lados, con modelos abiertos, costes competitivos y una lectura estratégica muy distinta del mercado.
El error sería elegir una IA como quien compra una camiseta de equipo. Para código complejo, Claude Opus 4.7 es una apuesta muy sólida. Para agentes que deben moverse por sistemas, GPT-5.5 tiene argumentos serios. Para contexto multimodal y análisis de grandes volúmenes de información, Gemini exige respeto. Para control, precio y despliegues menos dependientes de gigantes estadounidenses, los modelos abiertos ya no son decoración.
La IA útil no es la que gana una tabla aislada, sino la que falla menos en el trabajo que de verdad tienes delante. Y ahí Claude, con su aire de ingeniero que no presume demasiado pero revisa dos veces antes de tocar el cable, se ha ganado un sitio claro: no siempre es el más rápido, no siempre es el más vistoso, pero muchas veces es el que mejor entiende que programar no consiste en escribir código, sino en no romper lo que ya funcionaba.


AEO B2B: aparecer cuando la IA recomienda proveedores clave

Product graph ecommerce: datos que conectan todo tu catálogo

Content decay SEO: detectar artículos que pierden fuerza

Marketing mix modeling: medir sin cookies y con más contexto

Incrementalidad en Ads: saber qué ventas no habrían llegado

Prerendering SEO: servir HTML limpio sin matar velocidad

Search Console e IA: leer caídas sin culpar al algoritmo

SEO para snippets IA: respuestas breves con autoridad real

AEO para marcas: respuestas claras antes del clic orgánico

Devoluciones y SEO: datos que Google ya quiere leer bien

 Ecommerce
EcommercePara vender en Shopify hay que ser autónomo: respuesta legal
- IA y GEO
Comparativa de precios de plataforma IA: la factura real
- IA y GEO
Cómo aparecer y medir tu presencia en ChatGPT de verdad
- Web
Mejor CMS para SEO: la decisión que puede cambiar tu tráfico
- Web
Error 500 al guardar cambios en WordPress: solución real
- Google
Cómo conectar TikTok Ads a Google Sheets: rápido y bien
- SEO
Nombre de marca personal como estrategia SEO: gana clics
- SEO
Diferencia entre enlaces y señales SEO: qué influye de verdad en tu posicionamiento
- Contenidos
Generación de contenido con IA para negocios: riesgo y valor
- SEO
¿Cuál es elemento que tiene mayor relevancia para el SEO?
- Ecommerce
Cómo tener AliExpress conectado con Shopify sin fallos
- Web
Cómo añado los proyectos de Divi a Rank Math SEO sin fallos





















